
Updated for 2025. This how-to guide walks ecommerce leaders and builders through designing a production-safe GPT agent—complete with a practical specification template, defense-in-depth guardrails (prompt injection and PII/PCI protections), and a human-in-the-loop (HITL) handoff that protects CX and compliance. Expect copy-paste artifacts, acceptance criteria, verification steps, and an operations playbook.
- Who this is for: Product/engineering, CX/ops, and security/compliance teams at D2C brands, retailers, marketplaces, and manufacturers.
- Time and difficulty: Plan 2–4 sprints to reach a compliant MVP; complexity is high due to cross-functional coordination.
- Prerequisites: Access to your product catalog, order APIs, policy docs, helpdesk platform, logging/monitoring, and security sign-off for data handling.
Why this approach works: You’ll define scope clearly, anchor responses to vetted data, enforce PCI DSS v4.0 and privacy controls, and route edge cases to humans with explicit SLAs. These patterns reflect current industry guidance from PCI SSC, AWS, and leading security researchers.
1) Write the Agent Specification (copy-paste template inside)
Start with a tight scope and explicit acceptance criteria. This reduces hallucinations, prevents risky actions, and clarifies when to hand off to a human.
Spec Template (Edit and paste into your doc or ticket)
Title: Ecommerce GPT Agent – Customer Support & Product Discovery (MVP)
Owner: <PM/Architect> Reviewers: <CX Lead, Security, Compliance, Eng>
Version: v1.0 Target Go-Live: <date>
1. Objectives
- Deflect simple inquiries (FAQ, shipping, returns) while preserving CSAT.
- Help customers find products using catalog metadata.
- Provide authenticated order status via read-only API.
2. In-Scope Intents (MVP)
- FAQ: shipping times, return policy, warranty, store hours.
- Product discovery: attribute filters (size, color, compatibility), comparisons.
- Order status: “Where is my order?” with read-only tracking.
- Policy lookup: returns, exchanges, price match.
3. Out-of-Scope (must refuse and route)
- Accepting or transmitting payment card details in chat.
- Cancelling orders, changing addresses, or issuing refunds without human approval.
- Legal, medical, or safety-critical advice.
4. Channels & Tone
- Channels: Web widget (anon/auth), email assist, agent-assist in helpdesk.
- Tone: Clear, concise, friendly, accessible; avoid overpromising.
- Latency SLO: P50 ≤ 1.5s, P95 ≤ 3.0s end-to-end.
5. Ground Truth & Data Sources
- Product catalog + inventory (RAG index; refresh ≤ 24h).
- Policies & FAQ docs (curated, versioned, allowlisted).
- Order system (read-only status API).
6. Capabilities & Tool Permissions
- Retrieval: Only from allowlisted sources/domains.
- Tool calls: Read-only order status; NO write actions.
- Multilingual understanding; responses in user’s language when confident.
7. Safety & Compliance
- Prompt injection defenses; retrieval allowlist; output policy checks.
- PII/PCI: Detect and mask PAN before model calls; do not echo PAN.
- Consent & logging: Capture consent status; structured audit logs.
8. Acceptance Criteria (measurable)
- Intent accuracy ≥ 90% on top 10 intents (held-out eval).
- No unprotected PAN in logs or UI (0 incidents in pre-prod & first 30 days).
- Escalation trigger precision ≥ 0.85 on test set.
- Audit logs ≥ 99% completeness for required fields.
9. Handoff (HITL)
- Triggers: low confidence, high-risk intents, user asks for human.
- Transcript transfer: full chat, retrieved evidence, safety flags, consent.
- SLA: Business hours ≤ 2 min first response; after-hours ≤ 15 min or callback.
10. Telemetry & Ops
- Metrics: deflection rate, escalation rate, latency, safety flag rate.
- Circuit breakers: disable risky tools or retrieval on thresholds.
- Versioning: prompts, retrieval index, model, policy.
Pro tip: Keep a “won’t-do list” visible to all reviewers—if it’s not in scope, the agent refuses and offers a safe path.
Verification after drafting
- Reviewer sign-off: Product, CX, Security, Compliance initial approval.
- Dry run: Simulate 20 customer tasks and confirm in-/out-of-scope behavior.
- Acceptance tests: Run evals for intent accuracy, latency, escalation precision.
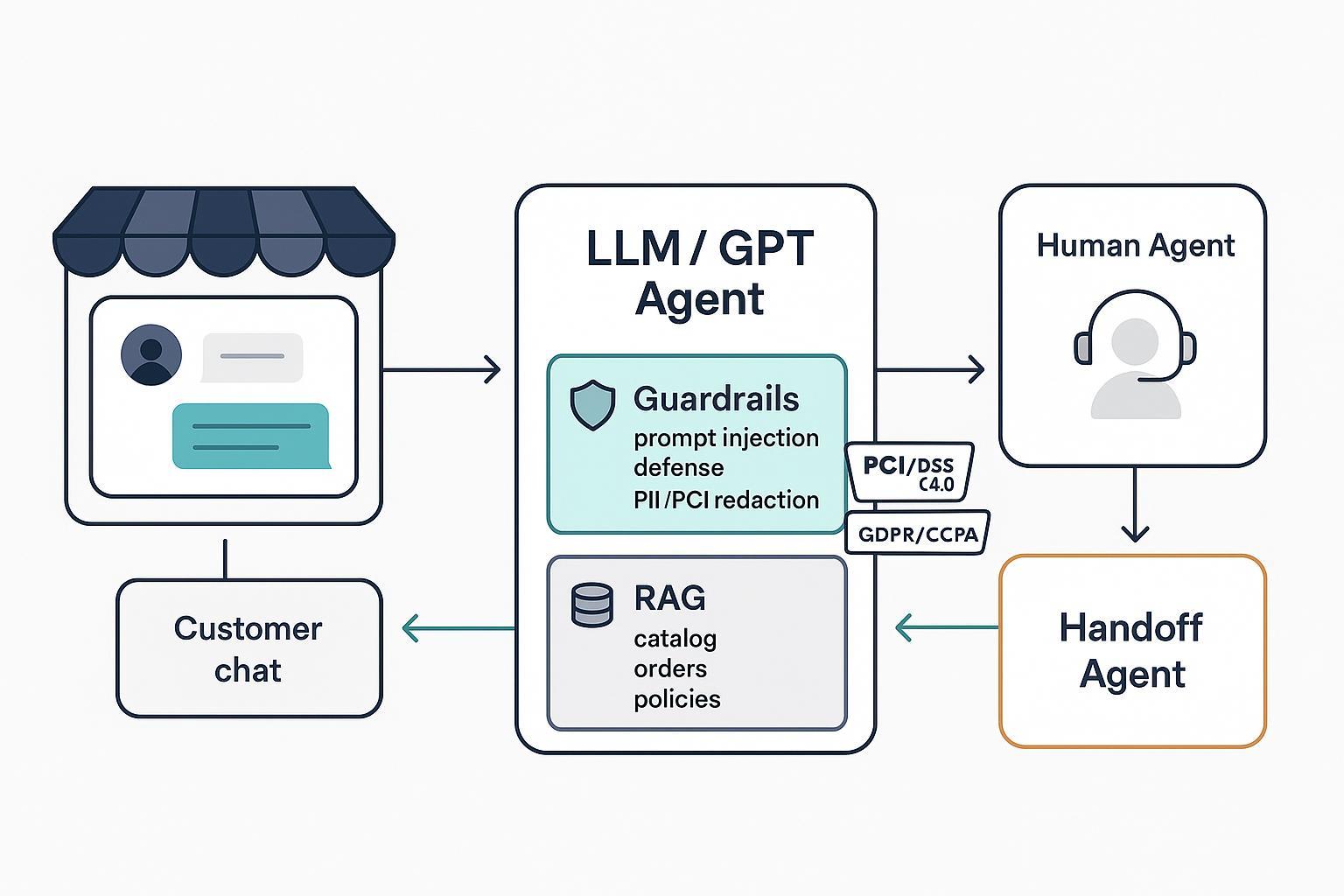
2) Build Guardrails that hold up in production
Your guardrails must cover prompt injection/jailbreaks, sensitive data handling (PCI/PII), and output quality. Follow defense-in-depth, with checks before, during, and after model calls.
2.1 Prompt injection and jailbreak defenses
Do this now:
- Harden the system prompt and isolate instructions. Treat system and developer messages as immutable. Avoid concatenating user-provided text into instruction slots. AWS’s 2025 guidance on building safe generative AI apps outlines layered guardrails and mediator patterns in practical terms (AWS machine learning blog, 2025).
- Restrict retrieval to allowlisted domains and curated corpora. Validate and sanitize HTML; unroll and validate shortened URLs; deny dangerous schemes. Lakera’s 2024–2025 work summarizes effective prompt injection mitigations and the risks of untrusted inputs (Lakera guide to prompt injection).
- Add canary tokens/leakage probes. Embed unique strings and monitor if they leak, and probe for instruction override paths. The 2024 ALERT benchmark highlights adversarial robustness testing for LLMs (Hugging Face ALERT benchmark, 2024).
- Use multi-layer detection. Combine heuristics (regex, conflict rules) with model-based detectors. Open-source projects like Rebuff implement detection pipelines and attack sandboxes (ProtectAI Rebuff on GitHub).
- Enforce a mediator for tools. Before any action, verify the intent matches a policy-allowed operation and require explicit confirmations for sensitive flows; log deny decisions.
Checkpoints where teams stumble
- Letting retrieval read from the open web. Restrict to vetted, versioned sources.
- “Self-policing” only. Don’t rely solely on the same LLM to detect its own prompts.
- Missing rollback. Keep prior prompt/model versions to revert quickly if exploitation is found.
Verification
- Red team with injection strings and jailbreak attempts; measure block rate and false positives. AWS security guidance on prompt injection countermeasures provides a good playbook (AWS Security blog, 2024).
- Run periodic leakage probes; alert if a canary appears in outputs.
2.2 PII/PCI controls aligned to PCI DSS v4.0
Key PCI DSS v4.0 requirements:
- Mask PAN when displayed (first 6 and last 4); render PAN unreadable wherever stored; protect transmission; do not send unprotected PAN via chat or other end-user messaging (PCI SSC Quick Reference Guide v4.0, 2024). The PCI Council reiterated these expectations in the v4.0.1 update and emphasized securing AI use in payment environments in 2025 (PCI SSC v4.0.1 announcement and PCI SSC AI-in-PCI guidance, 2025).
Implement this pipeline
- Pre-input: Warn users not to share card data in chat; if PAN-like input is detected, block, mask, and redirect to a secure checkout page.
- Ingress redaction: Before calling any model, detect PAN via pattern + Luhn and mask to first 6 + last 4; set redaction_event=true.
- Storage controls: Do not store full PAN in transcripts or logs. If tokens are needed, use vault tokenization. Encrypt at rest and in transit.
- Display masking: Ensure agent UI and human consoles never show full PAN; implement role-based reveal with logging.
- Output guard: Prevent the model from echoing detected PAN; replace with masked form and policy message.
Example: PAN detection + Luhn + masking (pseudocode)
import re
def luhn_check(digits: str) -> bool:
s = 0
alt = False
for d in reversed(digits):
n = int(d)
if alt:
n *= 2
if n > 9:
n -= 9
s += n
alt = not alt
return s % 10 == 0
PAN_REGEX = re.compile(r"\b(?:\d[ -]?){13,19}\b")
def mask_pan(text: str):
def repl(match):
raw = re.sub(r"[^0-9]", "", match.group(0))
if len(raw) < 13 or len(raw) > 19 or not luhn_check(raw):
return match.group(0) # not PAN
first6, last4 = raw[:6], raw[-4:]
masked_core = "*" * (len(raw) - 10)
return f"{first6}{masked_core}{last4}"
masked = PAN_REGEX.sub(repl, text)
redaction_event = masked != text
return masked, redaction_event
# Usage before any model call
masked_input, redacted = mask_pan(user_input)
if redacted:
log_event({"type": "redaction", "pii": ["PAN"], "reason": "PCI DSS 4.0"})
# Add user-facing guidance
Audit and logging fields to include
- request_id, session_id, timestamp, channel, model_provider/version
- prompt_template_id, retrieved_sources[], tool_calls[]
- redaction_events[] with masked_hash, pii_types[]
- safety_flags[], escalation_event{reason, confidence}
- consent_status, privacy_link_version
Verification
- Seed test chats with known PAN patterns; confirm masking and zero full PAN in logs.
- Confirm transport security and log retention settings in line with policy.
2.3 GDPR and CCPA/CPRA consent and logging
Do this to comply with privacy obligations and build trust:
- Provide clear notices at collection and log consent state. Under GDPR, ensure a lawful basis (consent, contract, or legitimate interests) and clear, accessible notices (Arts. 5, 6, 12–14). The European Data Protection Board reinforced transparency and legal basis expectations in 2024–2025 opinions; reference the primary text for exact obligations (EUR-Lex GDPR text).
- Support user rights and minimization. Enable access/correction/deletion of chat transcripts; set retention windows and purpose limits (GDPR Art. 5; DSAR readiness). See regulator materials from 2024–2025 on AI systems and records of processing (EDPB resources, 2025).
- For California, present notice at collection, handle sensitive personal information appropriately, and honor global privacy controls (GPC). The California Attorney General’s overview and CPPA regs cover these requirements (California AG CCPA overview and CPPA regulations hub).
Consent logging snippet (JSON)
{
"user_id": "<hashed>",
"session_id": "abc123",
"consent": {
"ai_assistance": {"status": "opt-in", "timestamp": "2025-09-13T10:22:00Z"},
"transcript_retention": {"status": "opt-in", "retention_days": 90},
"sale_share_opt_out": true,
"gpc_signal": true
},
"privacy_link_version": "v2025.1"
}
Verification
- Simulate a user opting out mid-chat; confirm routing to human and transcript handling changes.
- Test DSAR: Export, correct, and delete a user transcript within your SLA.
2.4 Output quality and hallucination reduction
- Retrieval-ground responses only. Cite retrieved source titles or identifiers where possible; avoid speculation when no evidence is found.
- Confidence-aware messaging. If confidence is low, present options or clarify, or route to a human.
- Brand/style guardrails. Keep tone and claims aligned with approved policy content; refuse beyond-scope requests.
3) Design Human-in-the-Loop (HITL) handoff that protects CX
Your goal is a seamless, transparent handoff while preserving safety and context for the human agent.
3.1 Triggers that must escalate
- Low confidence beneath threshold on an intent or answer.
- Repeated user frustration or negative sentiment over N turns.
- High-risk intents: refunds, address changes, warranty disputes, policy exceptions.
- Safety flags: harassment/hate, self-harm, threats.
- User request: “agent:human” or “talk to a human.”
Salesforce’s customer service guidance emphasizes escalation patterns and CX continuity in 2024–2025 resources (Salesforce Agentforce overview, 2025), while Zendesk’s 2025 guidance discusses AI-assisted routing and transparency (Zendesk AI customer service guide, 2025).
3.2 Handoff mechanics (what to pass along)
Handoff payload schema
{
"transcript": [ {"role": "user", "text": "..."}, {"role": "assistant", "text": "..."} ],
"retrieved_evidence": [ {"source_id": "policy-returns-v2025", "snip": "..."} ],
"intent": "refund_policy",
"confidence": 0.41,
"sentiment": "frustrated",
"customer": {"id": "u_987", "email": "masked@example.com"},
"consent_flags": {"ai_assistance": true, "retention": true},
"safety_flags": ["low_confidence"],
"last_tool_results": [{"tool": "order_status", "result": {"order_id": "o_123", "status": "in_transit"}}],
"sla_bucket": "business_hours",
"priority": "high",
"redaction_notes": ["PAN masked first6+last4"]
}
User-facing message during handoff
- “I’m transferring you to a human specialist now. It should take about 2 minutes. I’ve shared our conversation so you won’t need to repeat yourself.”
Verification
- Ensure no unprotected PAN or sensitive data in the payload.
- Confirm the helpdesk shows confidence score, reason for escalation, and evidence.
3.3 SLAs, capacity, and fallback
- Routing: Skills-based routing to best-fit agents; priority queues for safety or VIP customers.
- Hours: Business-hours vs. 24/7 staffing; define different SLA targets.
- Overflow: Offer callback scheduling, email capture, or ticket creation if queues exceed capacity targets.
- Fail-open vs. fail-safe: Default to fail-safe (escalate to human and limit agent scope) on safety incidents or model/vendor outages.
- Transparency: Inform users when a human takes over, provide a privacy link, and offer opt-out of AI handling where required.
OpenAI’s enterprise privacy commitments underscore transparency and control expectations in business settings (OpenAI Enterprise privacy commitments, 2025).
4) Monitor, Evaluate, and Operate
Strong ops prevent regressions and shorten incident recovery.
4.1 Pre-production
- Red teaming. Attempt prompt injections, jailbreaks, and PII/PCI leakage. Document findings and fixes. Use community evals like ALERT to stress-test defenses (Hugging Face ALERT benchmark, 2024).
- Acceptance tests. Validate intent accuracy ≥ 90% on top intents, escalation precision ≥ 0.85, P95 latency < 3.0s, and zero PAN exposure in logs.
- Prompt and policy registry. Version and review system prompts, tools, and allowlists.
4.2 Post-production observability
- Metrics to track: TTFT, end-to-end latency, tokens/request, error rates, deflection and escalation rates, safety flag rate, retrieval success rate.
- Dashboards and alerts. Centralize in your monitoring stack (CloudWatch, Arize, WhyLabs, or LangSmith). Annotate deployments and index refreshes. AWS prescriptive guidance covers observability patterns for agentic systems (AWS prescriptive guidance on observability, 2025).
- Structured logs. Include request_id, user/session, model version, prompt_template_id, retrieved sources, tool calls, redaction events, safety flags, escalation events, and output hashes; filter secrets and enforce retention.
4.3 Incident response and change management
- Circuit breakers: Auto-disable risky tools, tighten retrieval allowlists, switch to grounded templates when thresholds breach.
- Rollback and model fallback: Keep prior stable versions; downgrade to smaller or rules-based responses during incidents; escalate to human by default.
- Retrieval index freshness: Refresh product/policy indices within SLA (e.g., T+24h); verify with diff reports.
- Governance: Approvals for prompt changes; changelog for audits; link to risk register.
Toolbox: Stack options for building and operating your agent
Choose tools based on your environment, existing CX platforms, and compliance needs. Parity list (no endorsements):
- CX/helpdesk and HITL: Salesforce Service Cloud/Agentforce; Zendesk. See their 2025 resources on AI agents and escalation to align workflows (Salesforce Agentforce overview, 2025; Zendesk AI customer service guide, 2025).
- Monitoring/observability: Arize, WhyLabs, LangSmith. Instrument safety, latency, and deflection dashboards.
- LLM security/guardrails: Lakera, AWS Bedrock Guardrails, Rebuff.
- Data and workflow orchestration for ecommerce/ERP: WarpDriven can be used to unify product, order, inventory, and policy data for the agent. Disclosure: WarpDriven is our product.
Checklists and Templates you can use today
Guardrail checklist (MVP)
- Retrieval
- Allowlist domains and curated indices only; sanitize HTML/URLs; unroll short links
- Versioned corpora with T+24h freshness SLA
- Prompt security
- Hardened system/developer prompts; immutable instruction boundaries
- Canary tokens embedded; leak detection alerts
- PII/PCI pipeline
- Pre-input warning and block for PAN; regex+Luhn detection
- Mask first6+last4; no full PAN stored or displayed; TLS enforced
- Tokenization for any payment references; role-based reveal logging
- Privacy & consent
- Notice at collection; consent logging; GPC honor; DSAR workflows
- Retention policy enforced and visible to ops
- Output safety
- Refuse out-of-scope; confidence-aware messaging; regulated content filters
- Observability & IR
- Structured logs with redaction_events and safety_flags
- Dashboards for latency, deflection, escalations, and safety rates
- Circuit breakers and rollback playbook tested quarterly
HITL runbook (extract)
- Triggers: low confidence; frustration; high-risk intents; user request; safety flags
- Routing: skills-based with priority queues; VIP route faster
- Payload: full transcript, evidence, intent, confidence, safety flags, consent flags
- User messaging: transparent transfer + ETA; privacy link
- Capacity fallback: callback scheduling, email capture, ticket creation
- Post-handoff QA: Review 5% of escalations weekly; feed learnings into prompts & docs
Verification matrix (sample)
| Control | Test | Pass criteria |
|---|---|---|
| PAN masking | Seed card numbers | Only first6+last4 visible; logs show redaction_event |
| Prompt injection defense | Inject override strings | Block rate ≥ threshold; no system prompt leakage |
| Escalation precision | Low-confidence cases | Precision ≥ 0.85 on labeled set |
| Latency SLO | Load test | P95 < 3s end-to-end |
| Consent logging | Opt-out mid-chat | Routing switches; logs reflect updated consent |
| Retrieval allowlist | External URL bait | No unallowlisted links in outputs |
Troubleshooting guide
- Symptom: The agent cites outdated policy text.
- Fix: Tighten retrieval to the latest versioned corpus; add index freshness checks and annotations on deployments.
- Symptom: False positives on PII detection annoy users.
- Fix: Tune regex thresholds; add Luhn confirmation; allow user to rephrase and route to secure flows.
- Symptom: High escalation rate on product discovery.
- Fix: Improve attribute coverage in the catalog index; add disambiguation prompts and structured filters.
- Symptom: Occasional prompt leakage detected by canaries.
- Fix: Strengthen instruction isolation; update canary set; add post-processing policy checks; rotate prompts.
- Symptom: Vendor/model outage causes timeouts.
- Fix: Activate circuit breaker to fail-safe, switch to backup model or rules-based responses, and increase human staffing temporarily.
Next steps
- Finalize your spec with acceptance criteria and “won’t-do” list.
- Implement the redaction and allowlist pipelines first; then layer monitoring and HITL.
- Run a cross-functional pre-launch review with Security/Compliance and complete red-team exercises before go-live.
References (selected, 2024–2025)
- PCI masking, storage, and transmission rules: PCI SSC Quick Reference Guide v4.0 (2024) and PCI DSS v4.0.1 announcement (2025). AI use in payment environments: PCI SSC AI principles (2025).
- Prompt injection and guardrails: AWS guardrails blog (2025); AWS Security on prompt injection (2024); Lakera prompt injection guide (2024–2025); Hugging Face ALERT (2024); ProtectAI Rebuff.
- HITL and CX practices: Salesforce Agentforce overview (2025); Zendesk AI customer service guide (2025).
- Privacy: EUR-Lex GDPR text (consolidated, accessed 2025); EDPB resources (2024–2025); California AG CCPA overview and CPPA regulations hub (2025).