
If you want your SaaS product analytics pages to surface in AI Overviews and rich results, you need more than basic Product markup. In 2025, teams that win treat schema as an entity-centric system: a consistent, linked graph that mirrors the real-world relationships behind your product, data, and brand. Structured data won’t guarantee inclusion in AI features, but it materially improves how search systems parse, disambiguate, and trust your pages—when implemented with rigor and parity to on-page content, as Google’s own guidance emphasizes in its Introduction to structured data and the AI features in Search overview.
Below is the field-tested playbook I use with SaaS and eCommerce teams to build entity-rich markup for product analytics pages that maximizes eligibility, reduces errors, and scales across catalogs and releases.
Why entity-first schema wins in 2025
- Google still relies on structured data for understanding and eligibility of many rich results, with JSON-LD the recommended format. See Google’s Search Gallery of supported features for what’s eligible today.
- AI Overviews are algorithmic and cite web sources; schema helps search systems understand entities, relationships, and key facts. Google’s 2025 documentation on AI features in Search explicitly notes that markup aids understanding but doesn’t guarantee inclusion.
- FAQ rich results are restricted (since 2023 and reiterated in 2025), but FAQ markup still helps search engines understand page structure and can support help content. See Google’s June 2025 note on simplifying search results and the current FAQPage structured data doc.
- Industry tracking through 2024–2025 shows AI Overviews appearing in a notable share of queries, shifting click behavior; brands respond by leaning into structured content and eligibility for citations, per the Semrush AI Overviews study and iPullRank’s synthesis in Everything we know about AI Overviews.
Key takeaway: Treat your site as a knowledge graph. Represent your app, product, organization, and help content as linked entities that match what users actually see.
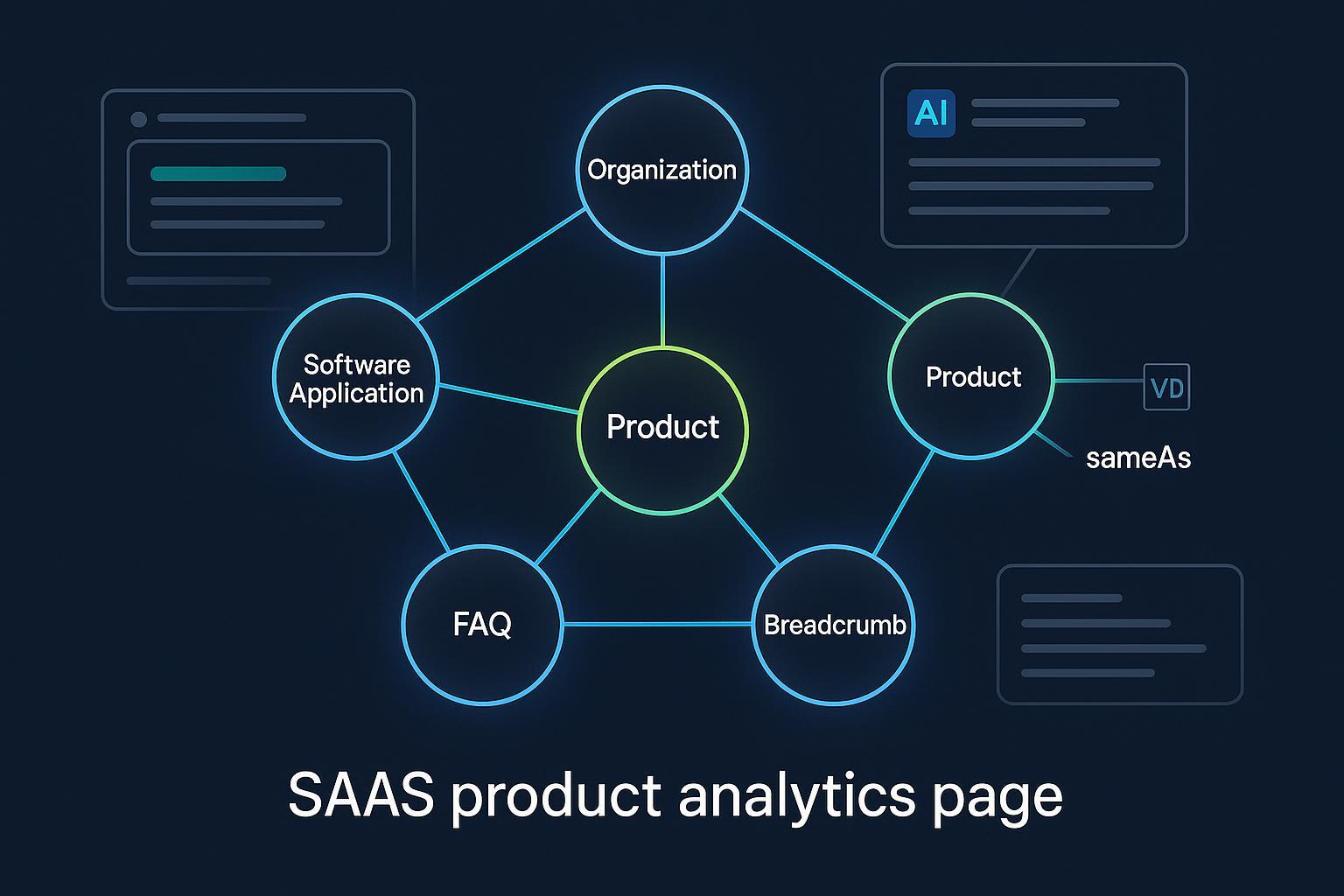
The entity model for product analytics pages
For SaaS analytics pages (features, dashboards, pricing, comparisons), deploy a layered model:
- Organization (or Brand): Publisher/vendor entity with logo, url, contactPoint, and sameAs links.
- SoftwareApplication (or WebApplication): Primary for SaaS. Include applicationCategory (e.g., AnalyticsApplication), operatingSystem (Web), offers, aggregateRating when compliant.
- Product: Commercial wrapper when needed for offer/availability scaffolding; reference the same app entity via @id.
- Review/AggregateRating: Only when policy-compliant and reflective of visible content; follow Google’s Review snippet guidelines.
- BreadcrumbList and ItemList: For feature lists, plan tiers, or comparison tables.
- FAQPage and HowTo: For onboarding and common questions. While widespread FAQ rich results are limited, markup still supports understanding of Q&A and task flow.
- DefinedTerm and Dataset: For analytics glossaries, metric definitions, or public methodology datasets.
Model it once, template it across pages, and keep identifiers stable.
Layered JSON-LD pattern (with @graph and stable @id)
Two practical deployment patterns work well:
- Consolidated @graph (one script per page)
- Split scripts (multiple JSON-LD blocks) joined by shared @id values
I prefer a consolidated @graph for ease of validation and portability. The crucial element is stable identifiers and correct relationships, per the W3C JSON-LD Best Practices.
Here’s an annotated example for a SaaS analytics page. Adjust properties to match your visible content and policies. Validate against Google’s SoftwareApplication and Product docs.
{
"@context": "https://schema.org",
"@graph": [
{
"@type": "Organization",
"@id": "https://example.com/#org",
"name": "Example Analytics Inc.",
"url": "https://example.com/",
"logo": {
"@type": "ImageObject",
"url": "https://example.com/static/logo.png"
},
"sameAs": [
"https://www.wikidata.org/wiki/Q123456",
"https://en.wikipedia.org/wiki/Example_Analytics",
"https://www.linkedin.com/company/example-analytics/",
"https://twitter.com/exanalytics"
]
},
{
"@type": ["SoftwareApplication", "Product"],
"@id": "https://example.com/#app",
"name": "Example Analytics Platform",
"applicationCategory": "BusinessApplication",
"operatingSystem": "Web",
"description": "AI-driven product analytics with cohort analysis, funnels, and retention reporting.",
"publisher": { "@id": "https://example.com/#org" },
"brand": { "@id": "https://example.com/#org" },
"offers": {
"@type": "Offer",
"price": "99.00",
"priceCurrency": "USD",
"priceSpecification": {
"@type": "UnitPriceSpecification",
"price": "99.00",
"priceCurrency": "USD",
"billingDuration": 1,
"billingPeriod": "https://schema.org/Month"
},
"url": "https://example.com/pricing",
"availability": "https://schema.org/InStock"
},
"aggregateRating": {
"@type": "AggregateRating",
"ratingValue": "4.7",
"reviewCount": "214"
}
},
{
"@type": "FAQPage",
"@id": "https://example.com/product-analytics/#faq",
"mainEntity": [
{
"@type": "Question",
"name": "How do I build a cohort report?",
"acceptedAnswer": {
"@type": "Answer",
"text": "Open Cohorts, select an event and time window, and segment by property or audience."
}
},
{
"@type": "Question",
"name": "Can I export raw event data?",
"acceptedAnswer": {
"@type": "Answer",
"text": "Yes, export via CSV or connect to your warehouse using our native connector."
}
}
]
},
{
"@type": "BreadcrumbList",
"itemListElement": [
{"@type": "ListItem", "position": 1, "name": "Products", "item": "https://example.com/products/"},
{"@type": "ListItem", "position": 2, "name": "Analytics", "item": "https://example.com/product-analytics/"}
]
}
]
}
Notes:
- The app is dual-typed (SoftwareApplication + Product) to satisfy both SaaS semantics and commercial offers; ensure consistency with visible content and validate in the Rich Results Test.
- Use @id fragments (#org, #app) to create stable, referenceable nodes across your site. Schema App explains the rationale in What is an @id in structured data?.
Implementation workflow that scales
A reliable rollout follows a repeatable workflow:
-
Discovery and content parity
- Inventory analytics pages (features, templates, dashboards, pricing, comparisons).
- Map visible content to schema properties. Parity matters for eligibility and trust, per Google’s structured data intro.
-
Template your entities
- Organization: Define once, site-wide. Keep sameAs high quality (Wikidata/Wikipedia, official social) and avoid irrelevant links. See guidance like sameAs schema best practices.
- SoftwareApplication/Product: Design a base template with required and recommended properties (offers, category, OS). Version it.
- FAQ/HowTo: Only for visible Q&A and real steps; don’t mark up hidden content. Visibility of FAQ rich results is limited, but markup aids understanding; refer to Google’s FAQPage doc.
-
Stage and validate
- Use Google’s Rich Results Test for eligibility checks and the Schema.org validator for vocabulary conformance. Fix missing required properties, invalid item types, and incorrect value types.
-
Ship with guardrails
- Ensure pages are indexable and not blocked. Include in XML sitemaps. Follow Google’s Search Gallery requirements for each type.
-
Monitor and iterate
- Track GSC Enhancements and manual actions. Log schema changes and correlate with impressions/clicks for affected pages.
- Adopt a quarterly audit baseline (monthly if pricing/features change frequently). Agencies report improved eligibility with consistent audits; see the 2025 overview in Schema markup tips for better eCommerce visibility.
-
Bake schema into CI/CD
- Lint JSON-LD; unit test required properties; fail builds on regressions. Keep a schema registry of templates and required/recommended fields per type.
External entity linking: disambiguation that earns trust
- Use sameAs to link your Organization and key People to authoritative profiles (Wikidata/Wikipedia, official social). Quality over quantity improves disambiguation, as discussed in Entity linking at scale.
- Keep @id stable and human-readable; refer to the W3C JSON-LD Best Practices for identifier design.
- Avoid spammy directories or irrelevant sameAs links; stick to canonical, authoritative sources.
Edge cases: headless, PWA, multilingual, and large catalogs
- Headless/PWA rendering: Prefer SSR or static generation so JSON-LD is included in the initial HTML. CSR-only injection risks delayed or missed parsing. See the DatoCMS overview on Headless CMS and SEO and SSR implementation notes in Best practices for optimizing SSR.
- Content modeling: Model schema fields in your CMS to map cleanly to Schema.org types and maintain referential integrity for @id. Useful patterns are discussed in Structuring content in a headless CMS and Strapi’s What is structured data.
- Multilingual: Localize name/description, use hreflang, and keep @id stable across locales (language-neutral identifiers).
- Large catalogs: Centralize templates, use partials for shared entities (Org, Brand), automate offers and availability, and schedule automated audits.
Privacy, compliance, and accessibility guardrails
- Only mark up information that is publicly visible on the page; avoid embedding PII or sensitive data in JSON-LD. This aligns with Google’s structured data policies and evolving privacy frameworks, such as the NIST Privacy Framework 1.1 update (2025) and state-level rules tracked by Osano’s US privacy law tracker.
- E-E-A-T signaling: Mark authorship and publisher using Person and Organization schema where relevant; link expert profiles via sameAs.
- Accessibility: Schema complements, not replaces, semantic HTML. Preserve headings, landmarks, and alt text; schema is additive metadata.
Common pitfalls to avoid
- Mismatch between markup and visible content (names, prices, claims). Leads to ineligibility or manual actions.
- Deprecated or unsupported types and properties. Cross-check with Google’s Search Gallery.
- Spammy sameAs links (low-quality directories) that confuse rather than clarify.
- CSR-only JSON-LD injection that arrives after indexing.
- Missing required properties (e.g., offers for Product-rich results) or incorrect value types (string where URL is required).
- Review/AggregateRating misuse (self-serving reviews or no visible review content) violating the Review snippet guidelines.
Toolbox: building and auditing schema at scale
Disclosure: The following are neutral examples; we may have affiliations. Choose based on scale, automation, and CMS fit.
- Merkle Schema Markup Generator — useful for creating quick, valid starters for common types.
- Schema App — robust modeling, governance, and enterprise workflows across large sites.
- WarpDriven — ERP/commerce-integrated schema orchestration for eCommerce/SaaS contexts; helpful when offers, inventory, and multi-site catalogs change frequently.
Consistent schema audits correlate with better eligibility and fewer errors in practice, as highlighted in the 2025 guidance on schema audits for eCommerce visibility. This is not a guarantee of AI Overview inclusion, but it improves data quality and discoverability.
Quick-win checklist (deploy in two sprints)
Sprint 1 (foundation)
- Define Organization once site-wide with stable @id and authoritative sameAs.
- Implement SoftwareApplication (primary) plus Product properties for offers; validate in the Rich Results Test.
- Add BreadcrumbList and ItemList where appropriate; ensure parity with navigation and lists.
- Ship JSON-LD in initial HTML (SSR/static), not via delayed CSR.
Sprint 2 (enhancements)
- Add compliant AggregateRating/Review only if visible and policy-aligned.
- Add FAQPage/HowTo for real, visible Q&A and task guides.
- Wire schema to CI/CD: lint, unit tests for required properties, and a template registry.
- Establish monitoring: GSC Enhancements, error logs, and a quarterly audit cadence (monthly for fast-changing catalogs).
Bonus: minimal HowTo snippet for an analytics task
Remember: mark up only what’s visible and reflect actual steps.
{
"@context": "https://schema.org",
"@type": "HowTo",
"name": "Create a retention cohort analysis",
"description": "Build a cohort report to measure user retention by signup month.",
"step": [
{"@type": "HowToStep", "name": "Open Cohorts", "text": "Navigate to Analytics → Cohorts."},
{"@type": "HowToStep", "name": "Select event", "text": "Choose the signup_completed event and a 6-month window."},
{"@type": "HowToStep", "name": "Segment", "text": "Segment by plan_tier and geography as needed."},
{"@type": "HowToStep", "name": "Export", "text": "Export CSV or push to your warehouse connector."}
]
}
Final recommendations
- Treat schema as product infrastructure, not a one-off task. Use stable @id, consistent entity relationships, and parity with on-page content.
- Validate before shipping and monitor after. Fix errors quickly and maintain a schema registry.
- Expect AI features to evolve. Schema supports understanding and eligibility, but inclusion is algorithmic; keep investing in helpful content and technical quality, guided by Google’s AI features overview.
If you implement the patterns above, your product analytics pages will be better understood by search systems, more resilient to changes, and more likely to be cited or featured where applicable.